Raku makes it easy to introduce a bit of parallelism into a program – at least, when the solution lends itself to that. Its asynchronous programming capabilities also shine when building concurrent applications. During the last year, I’ve enjoyed employing both of these in my work.
However, I also discovered that something was missing. It was relatively straightforward to build parallel and concurrent things what I wanted in Raku. However, once they were built, I found it hard to reason about what they were doing. For example:
For data parallel operations, what degree of parallelism was being achieved?
What tasks happened in parallel, and were there missed opportunities for further task parallelism?
Where was time being spent in different stages of an asynchronous workflow? For example, if a HTTP request could trigger background work, which later led to a message being sent over a WebSocket, where did the time go between these steps?
Given a Cro web application is also an asynchronous pipeline, where is time going on request processing? Is some piece of middleware surprisingly eating up a lot of time?
At first, I started putting in bits of timing code that wrote results out to the console. Of course, I either had to remove it again afterwards, or guard it with an environment variable if I wanted to keep it in the code. And even then, the data it produced was quite hard to interpret This all felt rather inefficient.
Thus, Log::Timeline was born. Using it, I learned a lot about my application’s behavior. Best of all, I didn’t just get answers to the questions I had, but also some that I hadn’t even considered asking. In this advent post, I’ll show how you can use this module also.
Trying it out
The first way we might make use of Log::Timeline doesn’t actually involve using the module at all, but rather using some library that already uses it to do logging. Since Cro::HTTP has done this (since 0.8.1), we can get our very first glimpse at Log::Timeline in action by building a Cro HTTP application.
The second thing we need is some way to view the logs. At present, there are two modes of Log::Timeline output: writing a file in JSONLines format or sending them over a socket. The second of these is used by the log viewer in Comma (a Raku IDE), meaning that we can view the output live as our application runs.
Thus, assuming we already installed Cro, we can:
Create a new Cro Web Application project in Comma (works much like using cro stub at the command line)
Create a “Cro Service” Run Configuration (choose Edit Configurations on the Run menu)
On the Run Menu, now choose “Run ‘service.p6’ and show Timeline”
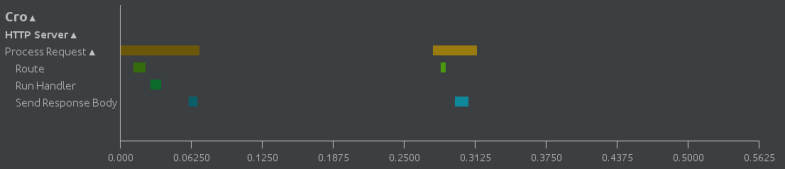
The service will start up, and display the URL it is running at in the console (probably http://localhost:20000). If we make a request to it, then flip to the Timeline tab, we’ll see the request logged (in fact, do it in a browser then probably two requests are logged, since a favicon.ico is automatically requested). The requests can be expanded to see how the processing time within them is spent.
Cro can process requests to HTTP application in parallel. In fact, it’s both concurrent (thanks to use of asynchronous I/O) and parallel (all steps of request processing are run on the Raku thread pool). So, if we use the Apache Benchmark program to send 100 requests, 3 at a time, we’d hope to see an indication that up to 3 requests were being processed in parallel. Here’s the command:
ab -n 100 -c 3 http://localhost:20000/
And we do, indeed, see the parallelism:
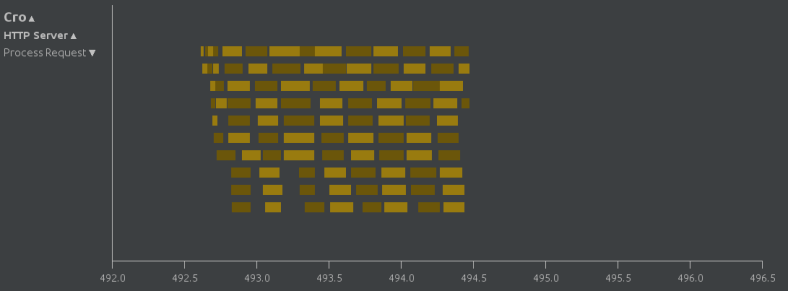
Similarly, if we jack it up to 10 concurrent requests:
ab -n 100 -c 10 http://localhost:20000/
Then we will see something like this:
Looking a little more closely, we see that the “Process Request” task is logged as part of the HTTP Server category of the Cro module. However, that’s not all: tasks (things that happen over a period of time) can also have data logged with them. For example, the HTTP request method and target are logged too:
We might also notice that requests are logged in alternating shades of color; this is to allow us to differentiate two tasks if they occur “back to back” with no time between them (or at least, none visible at our zoom level).
Adding Log::Timeline support to an application
What if we want to add Log::Timeline support to our own an application, so we can understand more about its behavior? To illustrate this, let’s add it to jsonHound. This is an application that looks through JSON files, and ensures that they are in compliance with a set of rules (its was built for checking the security of router configurations, but in principle could be used for much more).
When jsonHound is run, there are two steps:
Loading the rules, which are just written in Raku
Checking each specified JSON file against the rules; if there is more than one file, they will be checked in parallel
We’ll create a Log::Timeline task for each of these. These go into a JsonHound::LogTimelineSchema module. The code in the module looks like this:
unit moduleJsonHound::Logging;
use Log::Timeline;
classLoadRulesdoes Log::Timeline::Task["jsonHound", "Run", "Load Rules"] {
}
classCheckFiledoes Log::Timeline::Task["jsonHound", "Run", "Check File"] {
}
First, we use the Log::Timeline module. Then we create a class for each task that does the Log::Timeline::Task role (there is also an Event role, which can be used to log events that happen at a particular moment in time).
Next, we need to modify the program to use them. First, in the code we want to add logging to, we need to use our task schema:
use JsonHound::LogTimelineSchema;
And now we can go to work. Loading the ruleset looks like this:
my $*JSON-HOUND-RULESET = JsonHound::RuleSet.new;
my $rule-file = $validations.IO;
CompUnit::RepositoryRegistry.use-repository:
CompUnit::RepositoryRegistry.repository-for-spec(
$rule-file.parent.absolute);
require"$rule-file.basename()";
When we’re not running with any logging output, the block is just executed as normal. If, however, we were to have the socket output, then it would send a message out over the socket when the task begins, and another when it ends.
The per-file analysis looks like this:
.($reporter-object) for @json-files.race(:1batch).map:-> $file {
# Analysis code here
}
That is, we take the JSON files, and then map over them in parallel. Each produces a result, which we then invoke with the reporter. The exact details matter little; all we really need to do is wrap the analysis in our task:
.($reporter-object) for @json-files.race(:1batch).map:-> $file {
JsonHound::Logging::CheckFile.log: {
# Analysis code here
}
}
Handily, the log method passes along the return value of the block.
What we’ve done so far will work, but we can go one step better. If we look at the log output, we might see some input that takes a long time to process, but not be sure which one. We can annotate the log entry with whatever data we choose, simply by passing named arguments.
.($reporter-object) for @json-files.race(:1batch).map:-> $file {
JsonHound::Logging::CheckFile.log::$file, {
# Analysis code here
}
}
And with that, we’re ready! After adding a run configuration in Comma, and running it with the timeline viewer in, I get a chart like this:
The future
While Log::Timeline can already offer some interesting insights, there’s still plenty more functionality to come. Current work in progress uses a new MoarVM API to subscribe to GC events and send those over the timeline. This means it will be possible to visualize when GC runs and how much time is spent in it – and to correlate it with other events that are taking place.
I’m also interested in exposing various Rakudo-level events that could be interesting to see plotted on the timeline. With this, it may be possible to provide information on, for example, lock waiting times, or await times, or Supply contention times. Other ideas are plotting the times files or other resources are opened and closed, which may in turn help spot resource leaks.
Of course, just because there may be a wide range of things we could log does not mean they are all useful, and logging carries its own overhead. The use of the LogTimelineSchema naming convention looks forward to a further feature: being able to introspect the full set of events and tasks available. In Comma, we’ll then provide a UI to select them.
No small amount of the time we spend solving problems with our programs goes on finding out what is happening as they run. Good tooling can provide a window into the program’s behavior, and in some cases point out things that we might not even have considered. Log::Timeline is a pretty small module, and the visualizer didn’t take terribly long to implement either. However, the payback in terms of useful information makes it one of the most worthwhile thing I’ve built this year. I hope you might find it useful too.
This school semester I took my first proof-based class titled “Intro to Mathematical Proof Workshop”. After having taken other math classes (Calculus, Matrix Algebra, etc.), I felt that I didn’t have that much of a mathematical foundation and up to this point, all I had been doing was purely computational mathematics sprinkled with some proofs here and there. Looking back, I found the class quite enjoyable and learning about different theorems and their proofs, mostly from number theory, has given me a new perspective of mathematics.
“How is this related to Perl 6?”, you might be asking. As I mentioned, most of the proofs that were discussed either in class or left for homework were related to number theory. If there’s one thing Perl 6 and number theory have in common is their accessibility. Similar to how the content of the elementary theory of numbers can be tangible and familiar, Perl 6 can be quite approachable to beginners. In fact, beginners are encouraged to write what’s known as “baby Perl”.
Today, let me introduce Algorithm::LDA.
This module is a Latent Dirichlet Allocation (i.e., LDA) implementation for topic modeling.
Introduction
What’s LDA? LDA is one of the popular unsupervised machine learning methods.
It models document generation process and represents each document as a mixture of topics.
So, what does “a mixture of topics” mean? Fig. 1 shows an article in which some of the words are highlighted in three colors: yellow, pink, and blue. Words about genetics are marked in yellow; words about evolutionary biology are marked in pink; words about data analysis are marked in blue. Imagine all of the words in this article are colored, then we can represent this article as a mixture of topics (i.e., colors).
Fig. 1:
(This image is from “Probabilistic topic models.” (David Blei 2012))
OK, then I’ll demonstrate how to use Algorithm::LDA in the next section.
Modeling Quotations
In this article, we explore Wikiquote. Wikiquote is a cloud-sourced platform providing sourced quotations.
By using Wikiquote API, we get quotations that are used for LDA estimation. After that, we execute LDA and plot the result.
Finally, we create an information retrieval application using the resulting model.
Preliminary
Wikiquote API
Wikiquote has action API that provides means for getting Wikiquote resources.
For example, you can get content of the Main Page as follows:
{"batchcomplete":"","warnings":{"main":{"*":"Subscribe to the mediawiki-api-announce mailing list at <https://lists.wikimedia.org/mailman/listinfo/mediawiki-api-announce> for notice of API deprecations and breaking changes. Use [[Special:ApiFeatureUsage]] to see usage of deprecated features by your application."},"revisions":{"*":"Because \"rvslots\" was not specified, a legacy format has been used for the output. This format is deprecated, and in the future the new format will always be used."}},"query":{"pages":{"1":{"pageid":1,"ns":0,"title":"Main Page","revisions":[{"contentformat":"text/x-wiki","contentmodel":"wikitext","*":"
WWW by Zoffix Znet is a library which provides easy-to-use API for fetching and parsing json very simply.
For instance, as the README says, you can easily get content by jget(URL)<HASHKEY> style:
say jget('https://httpbin.org/get?foo=42&bar=x')<args><foo>;
NLTK is a toolkit for natural language processing.
Not only APIs, it also provides corpus.
You can get stopwords for English via “70. Stopwords Corpus”: http://www.nltk.org/nltk_data/
Exercise 1: Get Quotations and Create Cleaned Documents
At the beginning, we have to get quotations from Wikiquote and create clean documents.
The main goal of this section is to create documents according to the following format:
where get-members-from-category gets members via Wikiquote API:
sub get-members-from-category(Str $category -->List) {
my $member-url ="https://en.wikiquote.org/w/api.php?action=query&list=categorymembers&cmtitle={$category}&cmlimit=100&format=json";
@(jget($member-url)<query><categorymembers>.map(*<title>));
}
Next, call get-pages:
my @pages = get-pages(@members);
get-pages is a subroutine that gets pages of the given titles (i.e., members):
sub get-pages(Str @members, Int $batch =50-->List) {
myInt $start=0;
my @pages;
while $start< @members {
my $list = @members[$start..^List($start+ $batch, +@members).min].map({ uri_escape($_) }).join('%7C');
my $url ="https://en.wikiquote.org/w/api.php?action=query&prop=revisions&rvprop=content&format=json&formatversion=2&titles={$list}";
@pages.push($_) for jget($url)<query><pages>.map({ %(body =>.<revisions>[0]<content>, title =>.<title>) });
$start+= $batch;
}
@pages;
}
where @members[$start..^List($start + $batch, +@members).min] is a slice of length $batch, and the elements of the slice are percent encoded by uri_escase and joint by %7C (i.e., percent encoded pipe symbol).
In this case, one of the resulting $list is:
Note that get-pages subroutine uses hash contextualizer %() for creating a sequence of hash:
@pages.push($_) for jget($url)<query><pages>.map({ %(body =>.<revisions>[0]<content>, title =>.<title>) });
After that, we call create-documents-from-pages:
my @documents = create-documents-from-pages(@pages, @members);
create-documents-from-pages creates documents from each page:
sub create-documents-from-pages(@pages, @members -->List) {
my @documents;
for @pages -> $page {
my @quotations = $page<body>.split("\n")\
.map(*.subst(/\[\[$<text>=(<-[\[\]|]>+?)\|$<link>=(<-[\[\]|]>+?)\]\]/, { $<text> }, :g))\
.map(*.subst(/\[\[$<text>=(<-[\[\]|]>+?)\]\]/, { $<text> }, :g))\
.map(*.subst("[", "[", :g))\
.map(*.subst("]", "]", :g))\
.map(*.subst("&", "&", :g))\
.map(*.subst(" ", "", :g))\
.map(*.subst(/:i [ \<\/?\s?br\> | \<br\s?\/?\> ]/, "", :g))\
.grep(/^\*<-[*]>/)\
.map(*.subst(/^\*\s+/, ""));
# Note: The order of array wikiquote API returned is agnostic.myInt $index= @members.pairs.grep({ .valueeq $page<title> }).map(*.key).head;
@documents.push(%(body =>$_, personid => $index)) for @quotations;
}
@documents.sort({ $^a<personid> <=> $^b<personid> }).pairs.map({ %(docid =>.key, personid =>.value<personid>, body =>.value<body>) }).list
}
where .map(*.subst(/\[\[$<text>=(<-[\[\]|]>+?)\|$<link>=(<-[\[\]|]>+?)\]\]/, { $<text> }, :g)) and .map(*.subst(/\[\[$<text>=(<-[\[\]|]>+?)\]\]/, { $<text> }, :g)) are coverting commands that extract texts for displaying and delete texts for internal linking from anchor texts. For example, [[Perl]] is reduced into Perl. For more syntax info, see: https://docs.perl6.org/language/regexes#Named_captures or https://docs.perl6.org/routine/subst
After some cleaning operations (.e.g., .map(*.subst("[", "[", :g))), we extract quotation lines. .grep(/^\*<-[*]>/) finds lines starting with single asterisk because most of the quotations appear in such kind of lines.
Next, .map(*.subst(/^\*\s+/, "")) deletes each asterisk since asterisk itself isn’t a constituent of each quotation.
Finally, we save the documents and members (i.e., titles):
my $docfh =open"documents.txt", :w;
$docfh.say((.<docid>, .<personid>, .<body>).join("")) for @documents;
$docfh.close;
my $memfh =open"members.txt", :w;
$memfh.say($_) for @members;
$memfh.close;
Exercise 2: Execute LDA and Visualize the Result
In the previous section, we saved the cleaned documents.
In this section, we use the documents for LDA estimation and visualize the result.
The goal of this section is to plot a document-topic distribution and write a topic-word table.
The whole source code is:
usev6.c;
use Algorithm::LDA;
use Algorithm::LDA::Formatter;
use Algorithm::LDA::LDAModel;
use Chart::Gnuplot;
use Chart::Gnuplot::Subset;
sub create-model(@documents --> Algorithm::LDA::LDAModel) {
my $stopwords ="stopwords/english".IO.lines.Set;
my &tokenizer =-> $line { $line.words.map(*.lc).grep(-> $w { ($stopwords !(cont) $w) and $w !~~ /^[ <:S> | <:P> ]+$/ }) };
my ($documents, $vocabs) = Algorithm::LDA::Formatter.from-plain(@documents.map({ my ($, $, *@body) =.words; @body.join("") }), &tokenizer);
my Algorithm::LDA $lda .=new(:$documents, :$vocabs);
my Algorithm::LDA::LDAModel $model = $lda.fit(:num-topics(10), :num-iterations(500), :seed(2018));
$model
}
sub plot-topic-distribution($model, @members, @documents, $search-regex =rx/Larry/) {
my $target-personid = @members.pairs.grep({ .value~~ $search-regex }).map(*.key).head;
my $docid = @documents.map({ my ($docid, $personid, *@body) =.words; %(docid => $docid, personid => $personid, body => @body.join("")) })\
.grep({ .<personid> == $target-personid and.<body> ~~ /:i<< perl >>/}).map(*<docid>).head;
note("@documents[$docid] is selected");
my ($row-size, $col-size) = $model.document-topic-matrix.shape;
my @doc-topic =gatherfor ($docid X^$col-size) -> ($i, $j) { take $model.document-topic-matrix[$i;$j]; }
my Chart::Gnuplot $gnu .=new(:terminal("png"), :filename("topics.png"));
$gnu.command("set boxwidth 0.5 relative");
my AnyTicsTic @tics = @doc-topic.pairs.map({ %(:label(.key), :pos(.key)) });
$gnu.legend(:off);
$gnu.xlabel(:label("Topic"));
$gnu.ylabel(:label("P(z|theta,d)"));
$gnu.xtics(:tics(@tics));
$gnu.plot(:vertices(@doc-topic.pairs.map({ @(.key, .value.exp) })), :style("boxes"), :fill("solid"));
$gnu.dispose;
}
sub write-nbest($model) {
my $topics := $model.nbest-words-per-topic(10);
for^(10/5) -> $part-i {
say"|"~ (^5).map(-> $t { "topic { $part-i *5+ $t }" }).join("|") ~"|";
say"|"~ (^5).map({ "----" }).join("|") ~"|";
for^10-> $rank {
say"|"~gatherfor ($part-i *5)..^($part-i *5+5) -> $topic {
take@($topics)[$topic;$rank].key;
}.join("|") ~"|";
}
"".say;
}
}
sub save-model($model) {
my @document-topic-matrix := $model.document-topic-matrix;
my ($document-size, $topic-size) = @document-topic-matrix.shape;
my $doctopicfh =open"document-topic.txt", :w;
$doctopicfh.say: ($document-size, $topic-size).join("");
for^$document-size -> $doc-i {
$doctopicfh.say:gatherfor^$topic-size -> $topic { take @document-topic-matrix[$doc-i;$topic] }.join("");
}
$doctopicfh.close;
my @topic-word-matrix := $model.topic-word-matrix;
my ($, $word-size) = @topic-word-matrix.shape;
my $topicwordfh =open"topic-word.txt", :w;
$topicwordfh.say: ($topic-size, $word-size).join("");
for^$topic-size -> $topic-i {
$topicwordfh.say:gatherfor^$word-size -> $word { take @topic-word-matrix[$topic-i;$word] }.join("");
}
$topicwordfh.close;
my @vocabulary := $model.vocabulary;
my $vocabfh =open"vocabulary.txt", :w;
$vocabfh.say($_) for @vocabulary;
$vocabfh.close;
}
my @documents ="documents.txt".IO.lines;
my $model = create-model(@documents);
my @members ="members.txt".IO.lines;
plot-topic-distribution($model, @members, @documents);
write-nbest($model);
save-model($model);
First, we load the cleaned documents and call create-model:
my @documents ="documents.txt".IO.lines;
my $model = create-model(@documents);
create-model creates a LDA model by loading given documents:
sub create-model(@documents --> Algorithm::LDA::LDAModel) {
my $stopwords ="stopwords/english".IO.lines.Set;
my &tokenizer =-> $line { $line.words.map(*.lc).grep(-> $w { ($stopwords !(cont) $w) and $w !~~ /^[ <:S> | <:P> ]+$/ }) };
my ($documents, $vocabs) = Algorithm::LDA::Formatter.from-plain(@documents.map({ my ($, $, *@body) =.words; @body.join("") }), &tokenizer);
my Algorithm::LDA $lda .=new(:$documents, :$vocabs);
my Algorithm::LDA::LDAModel $model = $lda.fit(:num-topics(10), :num-iterations(500), :seed(2018));
$model
}
where $stopwords is a set of English stopwords from NLTK (I mentioned preliminary section), and &tokenizer is a custom tokenizer for Algorithm::LDA::Formatter.from-plain. The tokenizer converts given sentence as follows:
Splits given sentence by whitespace and makes a list of tokens.
Replaces each characters of the token with lower-case characters.
Deletes token that exists in the stopwords list or one-length token categorized as Symbol or Punctuation.
Algorithm::LDA::Formatter.from-plain creates numerical native documents (i.e., each word in a document is mapped to its corresponding vocabulary id, and this id is represented by C int32) and vocabulary from a list of texts.
After creating an Algorithm::LDA instance using the above numerical documents, we can start LDA estimation by Algorithm::LDA.fit. In this example, we set the number of topics to 10, and the number of iterations to 100, and the seed for srand to 2018.
Next, we plot a document-topic distribution. Before this plotting, we load the saved members:
my @members ="members.txt".IO.lines;
plot-topic-distribution($model, @members, @documents);
plot-topic-distribution plots topic distribution with Chart::Gnuplot:
sub plot-topic-distribution($model, @members, @documents, $search-regex =rx/Larry/) {
my $target-personid = @members.pairs.grep({ .value~~ $search-regex }).map(*.key).head;
my $docid = @documents.map({ my ($docid, $personid, *@body) =.words; %(docid => $docid, personid => $personid, body => @body.join("")) })\
.grep({ .<personid> == $target-personid and.<body> ~~ /:i<< perl >>/}).map(*<docid>).head;
note("@documents[$docid] is selected");
my ($row-size, $col-size) = $model.document-topic-matrix.shape;
my @doc-topic =gatherfor ($docid X^$col-size) -> ($i, $j) { take $model.document-topic-matrix[$i;$j]; }
my Chart::Gnuplot $gnu .=new(:terminal("png"), :filename("topics.png"));
$gnu.command("set boxwidth 0.5 relative");
my AnyTicsTic @tics = @doc-topic.pairs.map({ %(:label(.key), :pos(.key)) });
$gnu.legend(:off);
$gnu.xlabel(:label("Topic"));
$gnu.ylabel(:label("P(z|theta,d)"));
$gnu.xtics(:tics(@tics));
$gnu.plot(:vertices(@doc-topic.pairs.map({ @(.key, .value.exp) })), :style("boxes"), :fill("solid"));
$gnu.dispose;
}
In this example, we plot topic distribution of a Larry Wall’s quotation (“Although the Perl Slogan is There’s More Than One Way to Do It, I hesitate to make 10 ways to do something.”):
After the plotting, we call write-nbest:
write-nbest($model);
In LDA, what topic XXX represents is expressed as a list of words. write-nbest writes a markdown style topic-word distribution table:
As you can see, the quotation of “Although the Perl Slogan is There’s More Than One Way to Do It, I hesitate to make 10 ways to do something.” contains “one”, “way” and “perl”. This is the reason why this quotation is mainly composed of topic 8.
For the next section, we save the model by save-model subroutine:
sub save-model($model) {
my @document-topic-matrix := $model.document-topic-matrix;
my ($document-size, $topic-size) = @document-topic-matrix.shape;
my $doctopicfh =open"document-topic.txt", :w;
$doctopicfh.say: ($document-size, $topic-size).join("");
for^$document-size -> $doc-i {
$doctopicfh.say:gatherfor^$topic-size -> $topic { take @document-topic-matrix[$doc-i;$topic] }.join("");
}
$doctopicfh.close;
my @topic-word-matrix := $model.topic-word-matrix;
my ($, $word-size) = @topic-word-matrix.shape;
my $topicwordfh =open"topic-word.txt", :w;
$topicwordfh.say: ($topic-size, $word-size).join("");
for^$topic-size -> $topic-i {
$topicwordfh.say:gatherfor^$word-size -> $word { take @topic-word-matrix[$topic-i;$word] }.join("");
}
$topicwordfh.close;
my @vocabulary := $model.vocabulary;
my $vocabfh =open"vocabulary.txt", :w;
$vocabfh.say($_) for @vocabulary;
$vocabfh.close;
}
Exercise 3: Create Quotation Search Engine
In this section, we create a quotation search engine which uses the model created in the previous section.
More specifically, we create LDA-based document model (Xing Wei and W. Bruce Croft 2006) and make a CLI tool that can search quotations. (Note that the words “token” and “word” are interchangable in this section)
The whole source code is:
usev6.c;
sub MAIN(Str:$query!) {
my \doc-topic-iter ="document-topic.txt".IO.lines.iterator;
my \topic-word-iter ="topic-word.txt".IO.lines.iterator;
my ($document-size, $topic-size) = doc-topic-iter.pull-one.words;
my ($, $word-size) = topic-word-iter.pull-one.words;
myNum @document-topic[$document-size;$topic-size];
myNum @topic-word[$topic-size;$word-size];
for^$document-size -> $doc-i {
my \maybe-line := doc-topic-iter.pull-one;
die"Error: Something went wrong"if maybe-line =:= IterationEnd;
myNum @line =@(maybe-line).words>>.Num;
for^@line {
@document-topic[$doc-i;$_] = @line[$_];
}
}
for^$topic-size -> $topic-i {
my \maybe-line := topic-word-iter.pull-one;
die"Error: Something went wrong"if maybe-line =:= IterationEnd;
myNum @line =@(maybe-line).words>>.Num;
for^@line {
@topic-word[$topic-i;$_] = @line[$_];
}
}
my%vocabulary ="vocabulary.txt".IO.lines.pairs>>.antipair.hash;
my @members ="members.txt".IO.lines;
my @documents ="documents.txt".IO.lines;
my @docbodies = @documents.map({ my ($, $, *@body) =.words; @body.join("") });
my%doc-to-person = @documents.map({ my ($docid, $personid, $) =.words; %($docid => $personid) }).hash;
my @query = $query.words.map(*.lc);
my @sorted-list =gatherfor^$document-size -> $doc-i {
myNum $log-prob =gatherfor @query -> $token {
my Num $log-ml-prob = Pml(@docbodies, $doc-i, $token);
my Num $log-lda-prob = Plda($token, $topic-size, $doc-i, %vocabulary, @document-topic, @topic-word);
take log-sum(log(0.2) +$log-ml-prob, log(0.8) +$log-lda-prob);
}.sum;
take%(doc-i => $doc-i, log-prob => $log-prob);
}.sort({ $^b<log-prob> <=> $^a<log-prob> });
for^10 {
my $docid = @sorted-list[$_]<doc-i>;
sprintf("\"%s\" by %s %f", @docbodies[$docid], @members[%doc-to-person{$docid}], @sorted-list[$_]<log-prob>).say;
}
}
sub Pml(@docbodies, $doc-i, $token --> Num) {
my Int $num-tokens = @docbodies[$doc-i].words.grep({/:i^ $token $/ }).elems;
myInt $total-tokens = @docbodies[$doc-i].words.elems;
return-100e0if $total-tokens ==0or $num-tokens ==0;
log($num-tokens) -log($total-tokens);
}
sub Plda($token, $topic-size, $doc-i, %vocabulary is raw, @document-topic is raw, @topic-word is raw --> Num) {gatherfor^$topic-size -> $topic {
if%vocabulary{$token}:exists {
take @document-topic[$doc-i;$topic] + @topic-word[$topic;%vocabulary{$token}];
} else {
take-100e0;
}
}.reduce(&log-sum);
}
sub log-sum(Num $log-a, Num $log-b --> Num) {if $log-a < $log-b {
return $log-b +log(1+exp($log-a - $log-b))
} else {
return $log-a +log(1+exp($log-b - $log-a))
}
}
At the beginning, we load the saved model and prepare @document-topic, @topic-word, %vocabulary, @documents, @docbodies, %doc-to-person and @members:
my \doc-topic-iter ="document-topic.txt".IO.lines.iterator;
my \topic-word-iter ="topic-word.txt".IO.lines.iterator;
my ($document-size, $topic-size) = doc-topic-iter.pull-one.words;
my ($, $word-size) = topic-word-iter.pull-one.words;
myNum @document-topic[$document-size;$topic-size];
myNum @topic-word[$topic-size;$word-size];
for^$document-size -> $doc-i {
my \maybe-line = doc-topic-iter.pull-one;
die"Error: Something went wrong"if maybe-line =:= IterationEnd;
myNum @line =@(maybe-line).words>>.Num;
for^@line {
@document-topic[$doc-i;$_] = @line[$_];
}
}
for^$topic-size -> $topic-i {
my \maybe-line = topic-word-iter.pull-one;
die"Error: Something went wrong"if maybe-line =:= IterationEnd;
myNum @line =@(maybe-line).words>>.Num;
for^@line {
@topic-word[$topic-i;$_] = @line[$_];
}
}
my%vocabulary ="vocabulary.txt".IO.lines.pairs>>.antipair.hash;
my @members ="members.txt".IO.lines;
my @documents ="documents.txt".IO.lines;
my @docbodies = @documents.map({ my ($, $, *@body) =.words; @body.join("") });
my%doc-to-person = @documents.map({ my ($docid, $personid, $) =.words; %($docid => $personid) }).hash;
Next, we set @query using option :$query:
my @query = $query.words.map(*.lc);
After that, we compute the probability of P(query|document) based on Eq. 9 of the aforementioned paper (Note that we use logarithm to avoid undeflow and set the parameter mu to zero) and sort them.
my @sorted-list =gatherfor^$document-size -> $doc-i {
myNum $log-prob =gatherfor @query -> $token {
my Num $log-ml-prob = Pml(@docbodies, $doc-i, $token);
my Num $log-lda-prob = Plda($token, $topic-size, $doc-i, %vocabulary, @document-topic, @topic-word);
take log-sum(log(0.2) +$log-ml-prob, log(0.8) +$log-lda-prob);
}.sum;
take%(doc-i => $doc-i, log-prob => $log-prob);
}.sort({ $^b<log-prob> <=> $^a<log-prob> });
Plda adds logarithmic topic given document probability (i.e., lnP(topic|theta,document)) and word given topic probability (i.e., lnP(word|phi,topic)) for each topic, and sums them by .reduce(&log-sum);:
and Pml (ml means Maximum Likelihood) counts $token and normalizes it by the number of the total tokens in the document (Note that this computation is also conducted in log space):
sub Pml(@docbodies, $doc-i, $token --> Num) {
my Int $num-tokens = @docbodies[$doc-i].words.grep({/:i^ $token $/ }).elems;
myInt $total-tokens = @docbodies[$doc-i].words.elems;
return-100e0if $total-tokens ==0or $num-tokens ==0;
log($num-tokens) -log($total-tokens);
}
OK, then let’s execute!
query “perl”:
$ perl6 search-quotation.p6 --query="perl""Perl will always provide the null." by Larry Wall -3.301156
"Perl programming is an *empirical* science!" by Larry Wall -3.345189
"The whole intent of Perl 5's module system was to encourage the growth of Perl culture rather than the Perl core." by Larry Wall -3.490238
"I dunno, I dream in Perl sometimes..." by Larry Wall -3.491790
"At many levels, Perl is a 'diagonal' language." by Larry Wall -3.575779
"Almost nothing in Perl serves a single purpose." by Larry Wall -3.589218
"Perl has a long tradition of working around compilers." by Larry Wall -3.674111
"As for whether Perl 6 will replace Perl 5, yeah, probably, in about 40 years or so." by Larry Wall -3.684454
"Well, I think Perl should run faster than C." by Larry Wall -3.771155
"It's certainly easy to calculate the average attendance for Perl conferences." by Larry Wall -3.864075
query “apple”:
$ perl6 search-quotation.p6 --query="apple""Steve Jobs is the"With phones moving to technologies such as Apple Pay, an unwillingness to assure security could create a Target-like exposure that wipes Apple out of the market." by Rob Enderle -3.841538"*:From Joint Apple / HP press release dated 1 January 2004 available [http://www.apple.com/pr/library/2004/jan/08hp.html here]." by Carly Fiorina -3.904489"Samsung did to Apple what Apple did to Microsoft, skewering its devoted users and reputation, only better. ... There is a way for Apple to fight back, but the company no longer has that skill, and apparently doesn't know where to get it, either." by Rob Enderle -3.940359"[W]hen it came to the iWatch, also a name that Apple didn't own, Apple walked away from it and instead launched the Apple Watch. Certainly, no risk of litigation, but the product's sales are a fraction of what they otherwise might have been with the proper name and branding." by Rob Enderle -4.152145"[W]hen Apple wanted the name "iPhone" and it was owned by Cisco, Steve Jobs just took it, and his legal team executed so he could keep it. It turned out that doing this was surprisingly inexpensive. And, as the Apple Watch showcased, the Apple Phone likely would not have sold anywhere near as well as the iPhone." by Rob Enderle -4.187223"The cause of [Apple v. Qualcomm] appears to be an effort by Apple to pressure Qualcomm into providing a unique discount, largely because Apple has run into an innovation wall, is under increased competition from firms like Samsung, and has moved to a massive cost reduction strategy. (I've never known this to end well, as it causes suppliers to create unreliable components and outright fail.)" by Rob Enderle -4.318575"Apple tends to aggressively work to not discover problems with products that are shipped and certainly not talk about them." by Rob Enderle -4.380863"Apple no longer owns the tablet market, and will likely lose dominance this year or next. ... this level of sustained dominance doesn't appear to recur with the same vendor even if it launched the category." by Rob Enderle -4.397954"Apple is becoming more and more like a typical tech firm — that is, long on technology and short on magic. ... Apple is drifting closer and closer to where it was back in the 1990s. It offers advancements that largely follow those made by others years earlier, product proliferation, a preference for more over simple elegance, and waning excitement." by Rob Enderle -4.448473"[T]he litigation between Qualcomm and Apple/Intel ... is weird. What makes it weird is that Intel appears to think that by helping Apple drive down Qualcomm prices, it will gain an advantage, but since its only value is as a lower cost, lower performing, alternative to Qualcomm's modems, the result would be more aggressively priced better alternatives to Intel's offerings from Qualcomm/Broadcom, wiping Intel out of the market. On paper, this is a lose/lose for Intel and even for Apple. The lower prices would flow to Apple competitors as well, lowering the price of competing phones. So, Apple would not get a lasting benefit either." by Rob Enderle -4.469852 Ronald McDonald of Apple, he is the face." by Rob Enderle -3.822949"With phones moving to technologies such as Apple Pay, an unwillingness to assure security could create a Target-like exposure that wipes Apple out of the market." by Rob Enderle -3.849055"*:From Joint Apple / HP press release dated 1 January 2004 available [http://www.apple.com/pr/library/2004/jan/08hp.html here]." by Carly Fiorina -3.895163"Samsung did to Apple what Apple did to Microsoft, skewering its devoted users and reputation, only better. ... There is a way for Apple to fight back, but the company no longer has that skill, and apparently doesn't know where to get it, either." by Rob Enderle -4.052616"*** The previous line contains the naughty word '$&'.\nif /(ibm|apple|awk)/;# :-)" by Larry Wall -4.088445"The cause of [Apple v. Qualcomm] appears to be an effort by Apple to pressure Qualcomm into providing a unique discount, largely because Apple has run into an innovation wall, is under increased competition from firms like Samsung, and has moved to a massive cost reduction strategy. (I've never known this to end well, as it causes suppliers to create unreliable components and outright fail.)" by Rob Enderle -4.169533
"[T]he litigation between Qualcomm and Apple/Intel ... is weird. What makes it weird is that Intel appears to think that by helping Apple drive down Qualcomm prices, it will gain an advantage, but since its only value is as a lower cost, lower performing, alternative to Qualcomm's modems, the result would be more aggressively priced better alternatives to Intel's offerings from Qualcomm/Broadcom, wiping Intel out of the market. On paper, this is a lose/lose for Intel and even for Apple. The lower prices would flow to Apple competitors as well, lowering the price of competing phones. So, Apple would not get a lasting benefit either." by Rob Enderle -4.197869
"Apple tends to aggressively work to not discover problems with products that are shipped and certainly not talk about them." by Rob Enderle -4.204618
"Today's tech companies aren't built to last, as Apple's recent earnings report shows all too well." by Rob Enderle -4.209901
"[W]hen it came to the iWatch, also a name that Apple didn't own, Apple walked away from it and instead launched the Apple Watch. Certainly, no risk of litigation, but the product's sales are a fraction of what they otherwise might have been with the proper name and branding." by Rob Enderle -4.238582
Conclusions
In this article, we explored Wikiquote and created a LDA model using Algoritm::LDA.
After that we built an information retrieval application.
Thanks for reading my article! See you next time!
Citations
Blei, David M. “Probabilistic topic models.” Communications of the ACM 55.4 (2012): 77-84.
Wei, Xing, and W. Bruce Croft. “LDA-based document models for ad-hoc retrieval.” Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2006.
I’ve already mentioned Bisectable in one of the advent posts two years ago, but since then a lot has changed, so I think it’s time to give a brief history of the bisectable bot and its friends.
First of all, let’s define the problem that is being solved. Sometimes it happens that a commit introduces an unintended change in behavior (a bug). Usually we call that a regression, and in some cases the easiest way to figure out what went wrong and fix it is to first find which commit introduced the regression.
There are exactly 9000 commits between Rakudo 2015.12 and 2018.12, and even though it’s not over 9000, that’s still a lot.
A good amount of my work time this year has been spent on building a couple of Perl 6 applications. After a decade of contributing to Perl 6 compiler and runtime development, it feels great to finally be using it to deliver production solutions solving real-world problems. I’m still not sure whether writing code in an IDE I founded, using a HTTP library I designed, compiled by a compiler I implemented large parts of, and running on a VM that I play architect for, makes me one of the world’s worst cases of “Not Invented Here”, or just really Full Stack.
Whatever I’m working on, I highly value automated testing. Each passing test is something I know works – and something that I won’t break as I evolve the software in question. Even with automated tests, bugs happen, but adding a test to cover the bug at least means I’ll make different bugs in the future, which is perhaps a bit more forgivable. Continue reading “Day 22 – Testing Cro HTTP APIs”→
The year is ending and we have a lot to celebrate! What is a better way to celebrate the end of the year than with our family and friends? To help achieve that, here at my home, we decided to run a Secret Santa Game! So, my goal is to write a Secret Santa Program! That’s something where I can use this wonderful project called Red.
Red is an ORM (Object Relational Model) for perl6 still under development and not published as a module yet. But it’s growing and it is close to a release.
So let’s create our first table: a table that will store the people participating in our Secret Santa. To the code:
Advent is an exciting time, a time of anticipation. And not only for us humans — it is the time when elves become most inventive. Today, I want to take some leisure time out of the Christmas stress to report about some pioneering work that is being done in the area of gift wrapping. Even if you didn’t anticipate any news from there, this report might still help you improve your technique, as — I don’t have to remind you — Christmas is approaching fast.
Do you know which presents small children like most? Large presents. Therefore, the Present Enlargement Research Lab at Northpole is tasked with finding practical ways to make presents larger. Now, “large” can mean multiple things. I will admit that the 6th unit is bending the meaning a bit, but their work is by far the most interesting: they increase the volume of presents, by increasing the dimension of the gift boxes.
I am a big fan of roleplaying games like Dungeons and Dragons. Most of these games have screens to help you hide what you’re doing when running the game and give you some of the charts used in the game to reduce looking stuff up in the books.
My game collection is extensive though and I’d much rather use my laptop to not only hide behind and track information but I could also automate dice rolls and chart usage. Whilst I could cobble some stuff together with text editors and command line magic I’d much rather have some snazzy Desktops Apps that I can show off to people.
Enter GTK::Simple, a wrapper around the gtk3 UI library used by the Linux Gnome desktop but also available on Windows and Mac. This library gives you a simple to use interface, via the power of NativeCall, to let you create simple desktop applications.
Christmas trees are a traditional symbol that date back more than four hundred years in Europe, so what could be better for an advent article than something about creating Christmas tree images.
The typical, simplified, representation of the tree is several triangles of decreasing size stacked on top of each other with a small over-lap, so are fairly easy to create with a computer program.
Here I’ll use Scalable Vector Graphics (SVG) to draw the image as, given the description above, it seems perfectly suited to the task.